
Retrieval-Augmented Generation (RAG) is an extremely relevant process underlying nearly every AI project. But current RAG systems face significant limitations. Without RAG working properly, whatever you build on top of it will suffer.
Feature Augmented Retrieval provides a structured, explicit, and adaptive framework that significantly enhances retrieval accuracy and relevance.
Motivation
Information Retrieval systems are still far from perfect. They struggle when relying on all the raw, unstructured, or semi-structured data (text, images, tabular data) that is usually available. The usual approach of arbitrary combinations of different algorithms to mitigate those issues is still far from achieving great search accuracy and recall.
Also, document processing methods like naive chunking fail to address varying query intentions and contexts adequately, since there are queries that require a holistic understanding of several documents and parts of the same document in order to provide an accurate result.
On the other hand, a plain text user query with no domain-driven pre-processing provides a limited signal—its effectiveness is tied directly to your algorithm’s interpretative capabilities.
Existing retrieval methods (embeddings with cosine similarity, BM25F, or straightforward database filters) alone cannot consistently guarantee high accuracy or recall. Each retrieval approach is optimized for specific query aspects or scenarios, emphasizing the need for more nuanced methods.
Feature Extraction: Explicitly Structuring Data and Queries

Feature extraction is a technique that consists of transforming raw data into structured representations tailored for specific algorithms.
It is not new: it has been used in the Machine Learning and Data Science space, and it is part of the Feature Engineering discipline.
By applying effective Feature Extraction on Information Retrieval problems, you can reflect the domain knowledge in your data schema to then be able to divide the problem into smaller filtering problems, allowing you to rely on tailored approaches for each feature.
Also, it enables transparency and explicitness, since each of the filtering processes is pre-defined and not hidden within implicit algorithmic calculations that are difficult to interpret.
Query: “Red bag under 50€”
{
"plain_query": "red bag",
"color": "red",
"material": null,
"category": "bags",
"price": 50.0
}Product: “Scarlett Leather Tote”
{
"title": "Scarlett Leather Tote",
"image": "https://…",
"color": "scarlett",
"material": "leather",
"categories": ["bags", "totes"],
"suitability": ["night out", "formal"],
"product_summary": "..."
"price": 27.95
}By explicitly extracting structured features, you can design search engines that effectively filter, prioritize, and combine methods, significantly enhancing result relevance.
With the schema in the example, we would be able to generate filters and ranks for:
- Price, using a numeric comparison operator
- Color, by using a text similarity model or a classification agent
- Categories, by using algorithms like BM25F or SPLADE.
Feature Augmented Retrieval Architecture
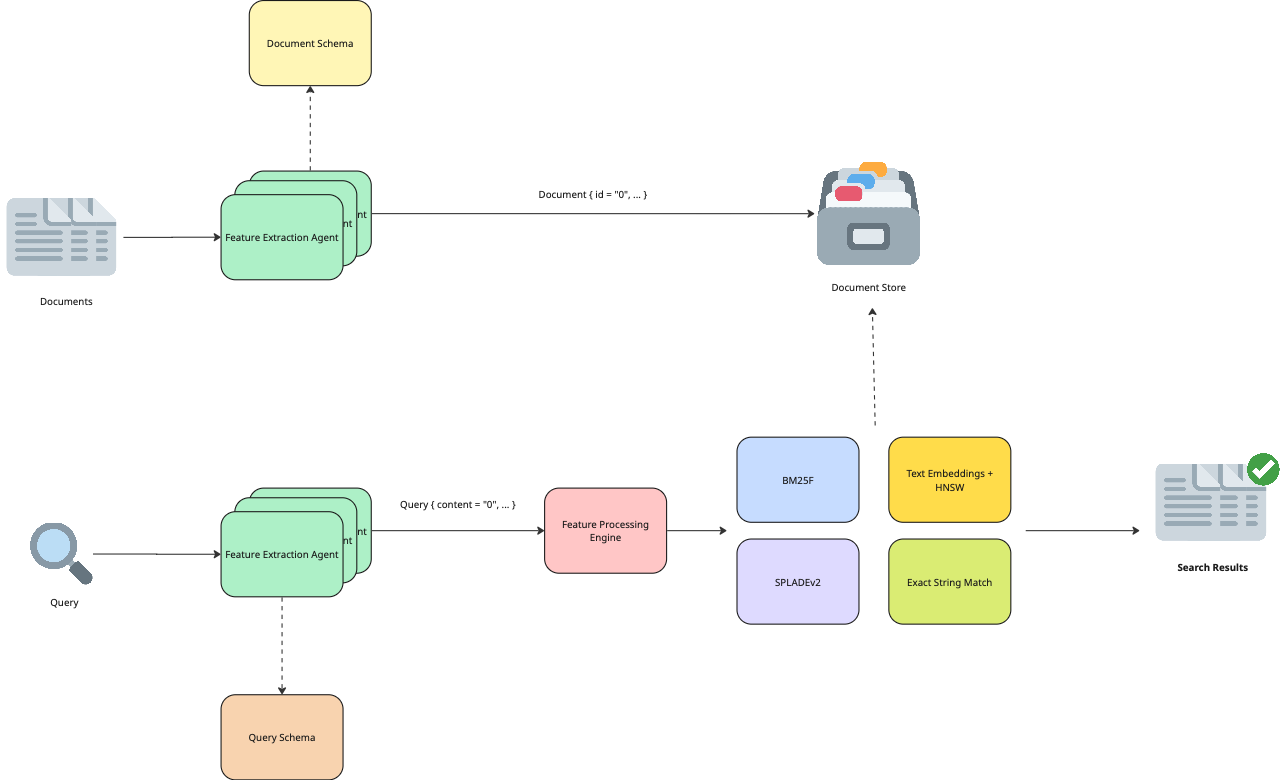
The architecture of Feature Augmented Retrieval includes:
- Document Schema: Defines the explicit structure and attributes of documents. Supports versioning for flexibility and incremental enhancements.
- Query Schema: Explicitly structures queries similarly to documents, improving interpretability and retrieval accuracy.
- Feature Extraction Agents: Specialized modules designed to extract structured attributes from raw inputs based on schema definitions.
- Feature Processing Engine: An adaptive component that selects and combines appropriate retrieval strategies based on extracted features.
- Retrieval Agents: Modular implementations of retrieval algorithms (e.g., BM25F, HNSW, Reciprocal Rank Fusion, Regex).
- Document Store: Repository optimized for structured storage and efficient retrieval.
Defining Effective Schemas
Schema definition should adopt a domain-driven approach:
- Align closely with business rules and user requirements.
- Identify necessary attributes based on concrete use cases.
- Consider technical capabilities (e.g., multimodal embeddings, summarization methods).
Evaluate schema necessity and granularity based on practical constraints and user query patterns.
- Is summarization needed? Do retrieval or generative models struggle with lengthy documents?
- Do user queries target holistic insights or specific document segments?
Crafting Robust Feature Extraction Agents
Feature extraction agents can initially leverage Large Language Models (LLMs) for rapid prototyping and validation. Building out a prompt using one state-of-the-art LLM and structured outputs enables a first point of validation:
- Latency and throughput performance.
- Accuracy and precision.
- Cost-efficiency and scalability.
Depending on this first version, you can then consider alternative solutions beyond LLMs:
- Named Entity Recognition (NER)
- Classifiers and supervised ML models
- Regular expressions (RegEx)
- Specialized algorithms
As always, to drive these decisions, a rigorous evaluation framework is critical, enabling iterative improvement and methodological comparisons.
Managing Cost and Latency: Caching
Apart from model distillation and alternative algorithms, to mitigate computational costs and latency, one of the best approaches is implementing multi-layered caching with customizable lifecycles, ensuring performance optimization and reliability.
Since each of the feature extraction agents is decoupled, it is feasible to build different cache units that are layered based on their processing orders and the input data needed.
Building a Dynamic Feature Processing Engine
The Feature Processing Engine orchestrates retrieval strategies, dynamically adapting based on query and document features.
To build your first processing engine, you need to design it based on the domain by thinking about how you should take advantage of the generated features to reduce the scope of the search process.
- Numeric or enumerated attributes: Often, simple database filters suffice.
- Concrete text features: BM25F or similar exact-match algorithms may be optimal.
- Query intention categorization. For example, for holistic or complex queries, a Combination of embedding-based retrieval with generative AI (LLMs) might be necessary.
The adaptability ensures high-quality retrieval regardless of query complexity.
Conclusion
By explicitly modeling and extracting structured attributes, organizations can deliver sophisticated, highly relevant retrieval systems tailored directly to business and user requirements. Feature Augmented Retrieval provides a structured, explicit, and adaptive framework that significantly enhances retrieval accuracy and relevance.