
Large Language Models have unlocked a new era in e-commerce search—one where user queries no longer need to be keyword-matched but can be truly understood. At The Agile Monkeys, we’ve been applying LLMs to bridge that intent gap: mapping fuzzy, multilingual, often messy user input to the structured data that powers great product discovery.
Our first approach was pragmatic—bundle all query understanding into a single, comprehensive prompt and let a general-purpose model handle it end-to-end. It worked. However, as traffic increased, so did latency, costs, and the complexity of debugging.
In this article, we explore a hypothesis: instead of shrinking prompts, what if we specialized our models? We put three approaches head-to-head:
- The Monolith: Our production GPT-4o mega-prompt (~2k tokens, does everything)
- Prompt-Only Specialists: Smaller GPT-4.1-nano models with task-specific prompts
- Fine-Tuned Specialists: The same nano models, but trained on our e-commerce data
Could a pipeline of smaller, focused tasks—especially those fine-tuned—outperform the monolith, not just in cost, but also in accuracy and agility? The results surprised us.
1 · The Monolithic Prompt Problem
Why LLMs for E-commerce Search?
Before diving into our architectural choices, it’s worth understanding why we need LLMs at all. Traditional e-commerce search relies on exact keyword matching or simple synonyms, but real users don’t speak in product catalog language.
Consider these real queries from our logs:
| User Query | Challenges | What LLMs Solve |
|---|---|---|
"coral summer dress" |
“Coral” isn’t in our color taxonomy | Maps coral → orange/red based on understanding |
"botas de montaña" |
Spanish query, plural form | Translates + singularizes: mountain boots → mountain boot |
"oversized hoodie XL" |
Mixed size formats | Recognizes both oversized and XL refer to size |
"denim jacket with pockets" |
“Denim” = material, “jacket” = type | Separates material from product type contextually |
"navy blue sneakers for running" |
Intent vs. attributes | Extracts navy (color), sneakers (type), ignores intent words |
"chihuahua bag black" |
“Chihuahua” = pattern or bag model? | Context determines: bag model vs. dog print pattern |
Each task requires linguistic understanding that traditional keyword matching can’t handle:
Translation & Normalization: Users search in their native language using colloquial terms. “Botas” needs translation, “dresses” needs singularization, and “sneakers” should map to “shoe” if that’s your taxonomy.
Color Intelligence: Fashion colors are notoriously subjective. Users say “coral,” “salmon,” “blush,” or “dusty rose” when they mean variations of pink/orange. An LLM can map these to your standardized color palette based on learned associations.
Product Type & Material Separation: When someone searches for “leather jacket,” they’re specifying both material (leather) and type (jacket). Rule-based systems struggle with composite queries like “waterproof hiking boots” where “waterproof” is a feature, “hiking” suggests usage, and “boots” is the type.
Size Flexibility: Users express size in countless ways: “XL,” “extra large,” “oversized,” “plus size,” “size 42,” “US 10.” Context matters—“42” means different things for shoes vs. jeans.
Our First Solution: The Mega-Prompt
Our e‑commerce search engine used to funnel every user query through a single, sprawling GPT‑4o prompt (~2K tokens). It juggled translation, product‑type parsing, attribute extraction, color detection—you name it. It worked… but at a cost:
- Latency ≈ 2 s per query
- Token bill ≈ 4× what we needed
- Debuggability ≈ 🤯
Why do these numbers matter? In an e‑commerce search, every 100 ms of extra latency can shave measurable points off conversion rate—shoppers bounce if results feel sluggish. Multiply a 2-second response time by millions of daily queries, and the lost basket recoveries add up to real revenue.
Cost follows the same power law. A single GPT‑4o call is inexpensive in isolation, but at peak, we could process millions of searches each month; at that scale, the prompt’s token bill balloons to a level that can materially impact the bottom line. When the model burns several times the tokens actually needed, optimization isn’t a luxury—it’s survival.
Another pain is debuggability. Because one mega‑prompt juggles multiple tasks, tweaking a line meant to improve the color extractor can unexpectedly break translation or product‑type parsing. Every prompt edit becomes a high‑stakes operation: you have to rerun complete end‑to‑end tests to make sure a fix in one corner hasn’t introduced regressions elsewhere.
We wondered: What if each sub‑task had its own lightweight brain?
2 · Hypothesis: Why Split the Prompt?
The Production Mega‑Prompt Baseline
In our live search engine we call GPT‑4o with a single ~2 000‑token prompt that does everything in one shot:
- System block – sets tone, locale rules, and defines a JSON schema with fields for
translated_query,product_type,material,size,primary_color, andsecondary_color. - Few‑shot examples – Few curated snippets covering edge cases like bilingual queries, hex color codes, and composite sizes.
- Reasoning instructions – e.g. “If the query contains multiple colors, choose the most visually dominant as
primary_color.”
The upside is simplicity: one call, one schema, predictable behaviour. The downside is girth—2000 tokens per request burns both time and money. That fat prompt is the monolith we’re trying to beat.
We believed that breaking the monolithic prompt into three purpose‑built calls would pay off in three ways:
Cheaper tokens, fewer of them. Each step runs on a GPT‑4.1‑nano, whose tokens cost a fraction of GPT‑4o’s. Combine that lower unit price with a much shorter context, and we expect a dramatic drop in total spend.
Win back time. Once the translator finishes, the product‑attribute extractor and the color extractor can run in parallel; even accounting for the extra round‑trips, we expected median latency to drop.
Make debugging sane. If the color taxonomy drifts or a new size label appears, we can retrain just that model without worrying about side effects on translation or type parsing.
3 · The Prompt‑Splitting Pipeline

Each stage runs on a GPT‑4.1‑nano variant:
Translator/Singularizer Prompt only • 384‑token context · 70 % accuracy (baseline numbers, see §4)
Type‑Material‑Size Prompt v Nano vs Finetuned Nano
Color Extractor Prompt v Nano vs Finetuned Nano
The final structured blob is passed to downstream retrieval.
What exactly does each model do?
| Stage | Task | Input → Output |
|---|---|---|
| 1. Translator | Detect language, translate to English, convert plurals to singular | "botas rojas" → "red boot" |
| 2. Product‑Type · Material · Size | Extracts product features that match on a set of the ecommerce rules | "red boot" → {type: "boot", material: "leather", size: null} |
| 3. Color Extractor | Extract primary/secondary colors based on a list of accepted colors | "red boot" → {primary: "red", secondary: []} |
Why translation quality matters: Stage 1 (translation) is the single upstream component.
The product‑type/size extractor and the color extractor run in parallel, but they both rely on the translator’s English output. If it mangles a key term—say "botas rojas" → "boats red"—both branches start from bad data. §4.3 quantifies this cascading‑error effect.
4 · Experimental Setup
Data Sourcing & Labelling
We captured **roughly 7000 real search queries** from a production logs cache, which is using the GPT-4o mega-prompt approach.
4o mega‑prompt bootstrap. Each query already flowed through our production GPT‑4o mega‑prompt, so we started from its JSON output (translated text + extracted attributes) instead of doing fresh heuristic translation.
Human clean‑up. Human annotators reviewed the auto‑generated JSON, fixed mistranslations, normalised terminology, and stripped any personal data.
Final verification. A third reviewer spot‑checked samples and resolved disagreements to lock in a “gold” label set.
| Item | Details |
|---|---|
| Train sets | 3 000 labelled queries per task |
| Eval/Dev | 350 queries per task |
| Test | ~350 unseen queries |
| Baselines | Full GPT‑4o mega‑prompt |
| Variants | 4.1‑nano with task‑only prompt · 4.1‑nano finetuned |
| Metrics | Exact‑match, Precision/Recall/F₁, latency |
Fine‑Tuning Strategy
Base: GPT‑4.1‑nano (128M‑token context)
Tool: OpenAI Platform
Hyper‑params: 3 epochs, batch 8, learning‑rate multiplier 0.1, model‑provided defaults elsewhere.
Why fine‑tune? In early prompt‑only trials, the color extractor confused near‑synonyms (burgundy, maroon), and the product extractor missed composite sizes (“S/M”). Fine‑tuning on curated data fixed both without inflating the prompt.
Metric Choices
| Metric | Why we picked it |
|---|---|
| Exact‑match accuracy | Harsh but informative: a pipeline run is useful only if all slots are correct. |
| Precision / Recall / F₁ per field | Lets us see whether a model is cautious (high precision) or aggressive (high recall). |
| Latency (avg / P95) | Directly correlates with user bounce rate in search. |
We logged metrics using a custom harness that replays the held-out test set against every variant, capturing the raw JSON output, token counts from the HTTP headers, and the client-side timer. All numbers in §5 come from the same test harness to ensure apples‑to‑apples comparison.
Hardware note: all calls run on OpenAI hosted endpoints; latency is measured client‑side.
5 · Results
5.1 · Product‑Type · Material · Size
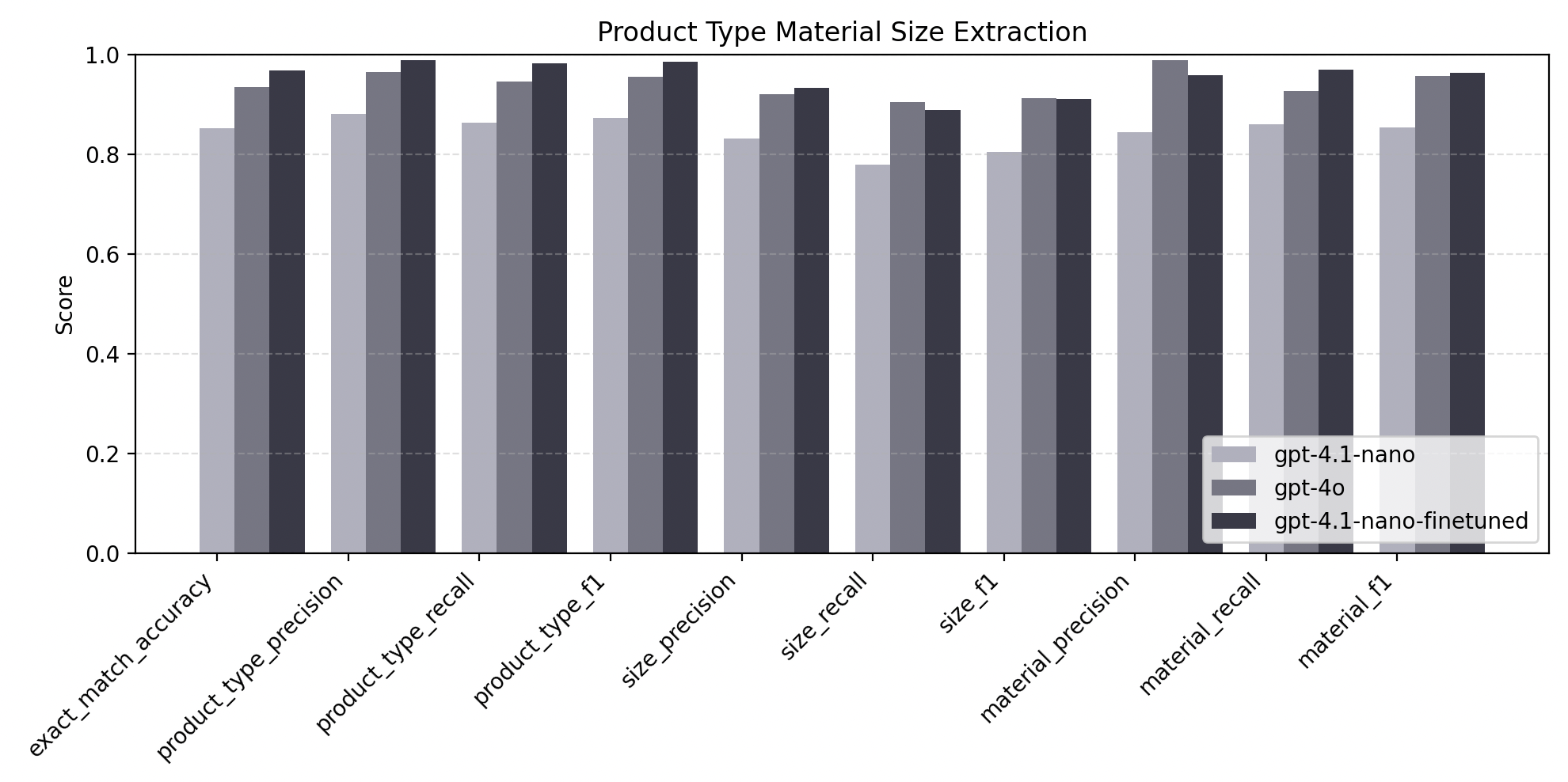
| Metric | 4o mega-prompt | 4.1‑nano | 4.1‑nano finetuned |
|---|---|---|---|
| Exact‑match | 0.94 | 0.87 | 0.96 |
| Product‑type F₁ | 0.96 | 0.93 | 0.98 |
| Size F₁ | 0.90 | 0.78 | 0.91 |
| Material F₁ | 0.96 | 0.86 | 0.96 |
| Latency (s) | 2.01 | 0.74 | 0.77 |
Takeaway: finetuning nudged nano past 4o in every metric while running ~3× faster.
5.2 · Color Extraction
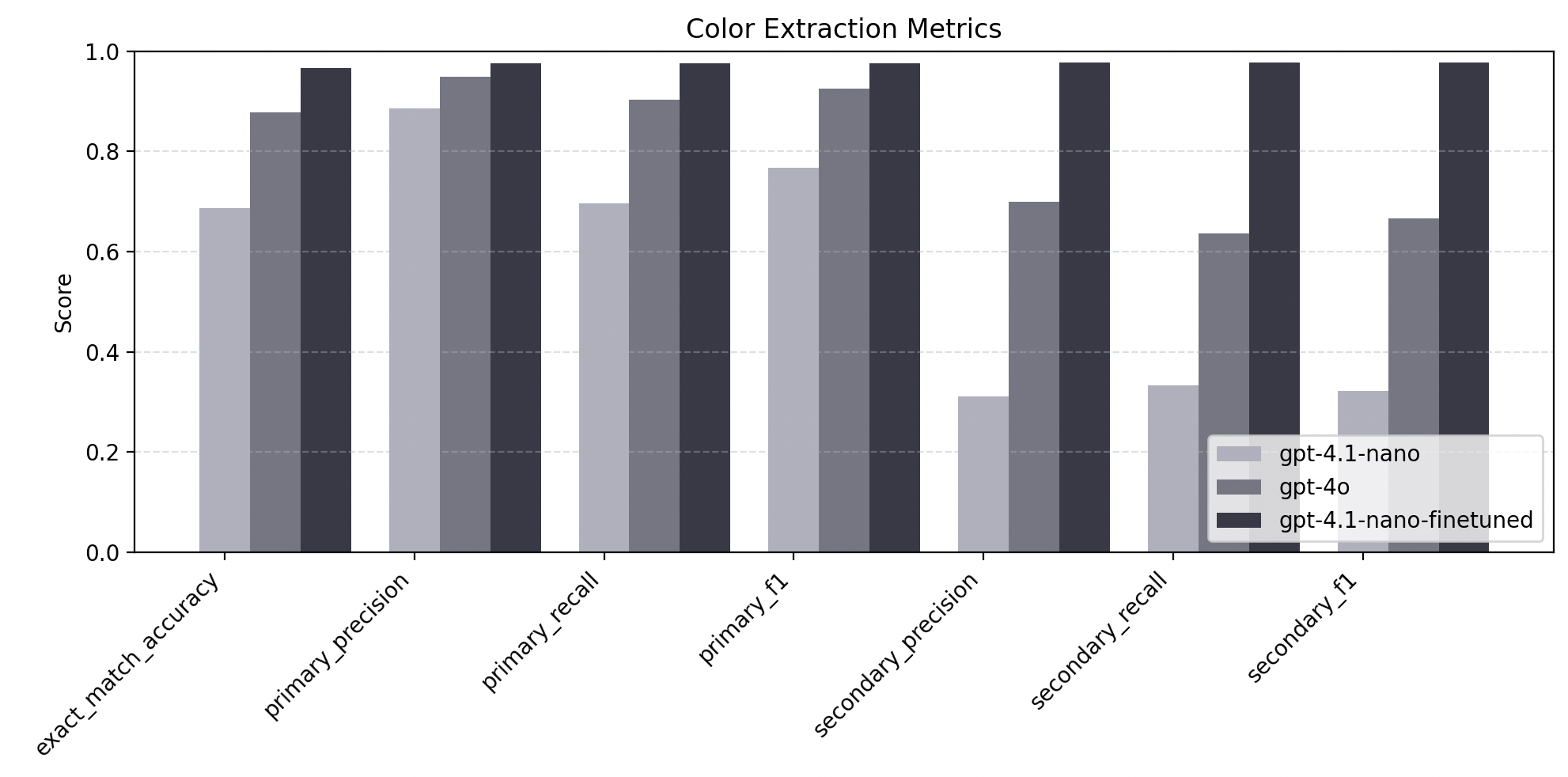
| Metric | 4o mega-prompt | 4.1‑nano | 4.1‑nano finetuned |
|---|---|---|---|
| Exact‑match | 0.88 | 0.69 | 0.99 |
| Primary F₁ | 0.91 | 0.77 | 0.99 |
| Secondary F₁ | 0.66 | 0.31 | 0.99 |
| Latency (s) | 1.98 | 0.57 | 0.57 |
// Best color‑extractor run
{
"exact_match_accuracy": 0.9886,
"primary_colors": { "precision": 0.9895, "recall": 0.9930, "f1": 0.9912 },
"secondary_colors": { "precision": 1.0, "recall": 0.9767, "f1": 0.9882 },
"latency_s": { "avg": 0.57, "min": 0.46, "max": 1.53 }
}5.3 · End‑to‑End Pipeline Accuracy (Specialised stack vs. Monolith)
This table measures the whole search pipeline in one shot, chaining the three specialist models and comparing that against the single GPT‑4o prompt.
| Pipeline | Translator variant | Accuracy | Avg Latency (s) | Test cases |
|---|---|---|---|---|
| 4o mega-prompt | Built‑in (same model) | 91 % | 1.25 | 165 queries |
| Specialized v1 | 4.1‑nano • 70 % acc | 55 % | 1.07 | 20 queries |
| Specialized v2 | 4.1‑nano (better prompt) | 79 % | 2.22 | 165 queries |
What actually happened in v1? The pipeline executes strictly left‑to‑right, so the translator’s output becomes the single source of truth for every downstream extractor. When that first translator was hitting only ≈ 70 % accuracy, roughly 1 in 3 queries arrived garbled — and every mis‑translation poisoned the rest of the chain. End‑to‑end accuracy collapsed to 55 %.
Cascading‑error anatomy
"botas rojo"→ mistranslated as"boats red"→ product‑type extractor can’t map “boats”.- Color extractor never sees rojo → misses the primary color.
- The scoring script flags the entire prediction as wrong.
We changed only one component — swapping in a prompt‑engineered 4.1‑nano translator that lifts translation accuracy to ≈ 80 % — and the pipeline instantly climbed to 79 % overall: a 24‑percentage‑point jump. The moral: in chained LLM systems, the weakest link sets the ceiling.
We still trail the monolith by ~12 pp, so the next milestone is a finetuned translator plus confidence‑based fallbacks to GPT‑4o.
6 · Analysis
- Finetuning > prompting. Even a tiny 4.1‑nano crosses 98 % accuracy once trained on 3k rows.
- Cost drops ~4×. Nano tokens are cheaper, and we eliminated the shared boilerplate prompt.
- Latency becomes predictable. 95th percentile now < 1s without retries.
- Weak spot (still): translation remains the bottleneck. The first 70% translator dragged the pipeline to 45% E2E accuracy; a quick prompt tweak lifted us to 79%, confirming the cascading-error hypothesis. A fine-tuned translator and confidence routing are next on the queue.
7 · Conclusion & Next Steps
Splitting the mega‑prompt into specialised nanos gave us 4× cheaper calls, 3× faster responses, and better extraction quality—once we fine‑tuned. But both approaches have their strengths and weaknesses.
Monolithic GPT‑4o mega‑prompt
- One‑stop speed. A single API round‑trip handles translation, parsing, and color logic, so median latency is often the lowest of all options.
- Coherent context. Every sub‑task shares the same prompt and conversation state—no mismatched assumptions.
- But fragile coupling. One prompt tweak can break five behaviours; regression tests are non‑negotiable.
- Ideal for prototypes & low‑traffic workloads where simplicity trumps penny‑pinching.
Specialised micro‑model pipeline
Cheaper tokens, modular bills. Nano models are inexpensive, and you only pay for the tasks you invoke.
Edit in isolation. Retrain or prompt‑tune the color extractor without touching translation or type parsing.
Faster on average, spikier in tail. Parallel small calls can beat one big call, but orchestration adds a bit of jitter.
Observability wins. Stage‑level metrics make root‑cause analysis trivial when something drifts.
Latency & cost efficiency. Roughly 3× faster and 4× cheaper once fine‑tuned.
Debuggability & modularity. Each stage is observable; you can swap or retrain a single link without touching the rest.
Scales gracefully when traffic or taxonomy complexity explodes—just shard more tasks.
Practical heuristic: Start monolithic to prove the UX; migrate to specialization once cost, latency, or observability hits a wall.
Still a work in progress 🚧 The numbers above are a snapshot, not the finish line. We’re sharing them now to surface the trade‑offs we uncovered and spark discussion. Accuracy, stability, and translator quality will continue to improve as we iterate, so feel free to point out any areas for improvement in our approach.