
In fashion e-commerce, neither image-only nor text-only embeddings capture the full spectrum of cues hidden in brand marketing language and product photography. We show that early fusion by concatenating a CLIP image vector with a large‑language‑model text vector lifts full‑ranking nDCG from 0.738 → 0.842 —a +14 % relative gain over the image baseline and +3 % over a strong text baseline—while a naïve weighted‑sum late‑fusion yields a smaller +9 % lift. The recipe adds two lines of Python and no extra training, yet leaves ample headroom for supervised fine‑tuning and learned fusion.
1 Motivation
A shopper types “oversized off‑white tee with crew neck”.
The catalogue, however, says:
- Colour: stone — not off‑white
- Style notes: loose fit, boyfriend cut
- Image: crew neck visible, but not part of the product information.
Keyword search collapses; a single embedding model still misses half the picture.
The pragmatic question:
How far can we get by blending two complementary off‑the‑shelf encoders before investing in task‑specific training?
2 Experimental Set‑up
| Component | Specification |
|---|---|
| Catalogue | proprietary fashion dataset, ≈ 10k SKUs |
| Image encoder | laion‑CLIP‑ViT‑bigG‑14‑laion2B‑39B‑b160k |
| Text encoder | text‑embedding‑3‑large over the concatenation of: • name • description • product_type • primary_color • secondary_color |
| Similarity metric | Brute-force cosine similarity (exact search) |
| Evaluation | nDCG over the full ranked list |
| Queries & labels | mixture of synthetic and expert‑verified relevance judgments |
| Hardware | Single workstation GPU (RTX 4090) for embedding; CPU for search |
3 Fusion Strategies
3.1 Early Fusion (Concatenation)
Early fusion joins the two embedding spaces end‑to‑end. If the image encoder lives in \(\mathbb{R}^{d_1}\) and the text encoder in \(\mathbb{R}^{d_2}\), the concatenated vector \(z = [alpha\, \hat x,\, eta\, \hat y] \in \mathbb{R}^{d_1+d_2}\) is searched with plain cosine similarity.
Why does this help?
- Complementary neighborhoods – an item that is close in either modality rises in the joint rank.
- Additive kernel view: cosine in the fused space is exactly \(K = alpha^{2}K_{ ext{img}} + eta^{2}K_{ ext{text}}\) the better kernel dominates automatically.
- Capacity bump – doubling dimensionality roughly doubles the linear decision surface, separating confounding categories such as colour versus cut.
- Noise averaging – distances coming from partly independent sub‑spaces reduce variance, lowering false negatives at fixed
k.
Amazingly, a default \(alpha=eta=1\) already delivers most of the benefit.
import numpy as np
import faiss
import clip, torch, openai
# --- 1. encode ---------------------------------------------------------------
device = "cuda" if torch.cuda.is_available() else "cpu"
# Image embedding
clip_model, clip_preprocess = clip.load("ViT-bigG-14", device=device)
def encode_image(path):
img = clip_preprocess(PIL.Image.open(path)).unsqueeze(0).to(device)
with torch.no_grad():
vec = clip_model.encode_image(img).squeeze().cpu().numpy()
return vec / np.linalg.norm(vec)
# Text embedding (OpenAI)
def encode_text(text):
resp = openai.embeddings.create(
model="text-embedding-3-large",
input=text,
)
vec = np.array(response.data[0].embedding, dtype=np.float32)
return vec / np.linalg.norm(vec)
# --- 2. early fusion ---------------------------------------------------------
def concat_fusion(img_vec, txt_vec, alpha=1.0, beta=1.0):
return np.concatenate([alpha * img_vec, beta * txt_vec]).astype("float32")
# Example
img_vec = encode_image("sku_123.jpg")
txt_fields = [name, description, product_type, primary_color, secondary_color]
txt_vec = encode_text(" ".join(txt_fields))
z = concat_fusion(img_vec, txt_vec)Add to FAISS
# cosine because vectors are L2‑normalised
index = faiss.IndexFlatIP(z.size)
# add all catalogue vectors
index.add(np.stack([z, ...]))
# retrieve top‑50
D, I = index.search(query_vecs, k=50)Engineering cost: two extra lines after the normalisation step.
3.2 Late Fusion (Weighted Sum)
Late fusion keeps the dimensionality unchanged: the two vectors are blended in place.
\(z_\lambda = \lambda\,\hat x + (1-\lambda)\,\hat y ,\quad z_\lambda\in\mathbb{R}^{d}.\)
The idea resides in taking advantage of the two-tower architecture of CLIP and fusing both the image characteristics and the product information characteristics using the same model.
Intuitively, this draws a straight line between the image and text points. If their nearest neighbors differ, the midpoint can end up between both relevant clusters, diluting precision.
def weighted_sum(img_vec, txt_vec, lam=0.5):
return (lam * img_vec + (1 - lam) * txt_vec).astype("float32")
# simple λ grid‑search on a held‑out set
lams = np.linspace(0.1, 0.9, 9)
best_lam, best_score = None, -np.inf
for lam in lams:
fused = np.stack([weighted_sum(iv, tv, lam) for iv, tv in zip(img_vecs, txt_vecs)])
# user‑provided evaluation routine
score = evaluate_nDCG(fused)
if score > best_score:
best_lam, best_score = lam, score
print(f"best λ = {best_lam:.2f}")A light grid search usually nudges nDCG a couple of points above the naïve λ = 0.5 setting, but in our catalogue still trails concatenation.
4 Results
| Method | nDCG (full) | Relative Δ vs. CLIP |
|---|---|---|
| CLIP image only | 0.738 | — |
| text‑embedding‑3‑large only | 0.819 | +11 % |
| Weighted sum (λ ≈ 0.5) | 0.803 | +9 % |
| Concatenation (α = β = 1) | 0.842 | +14 % |
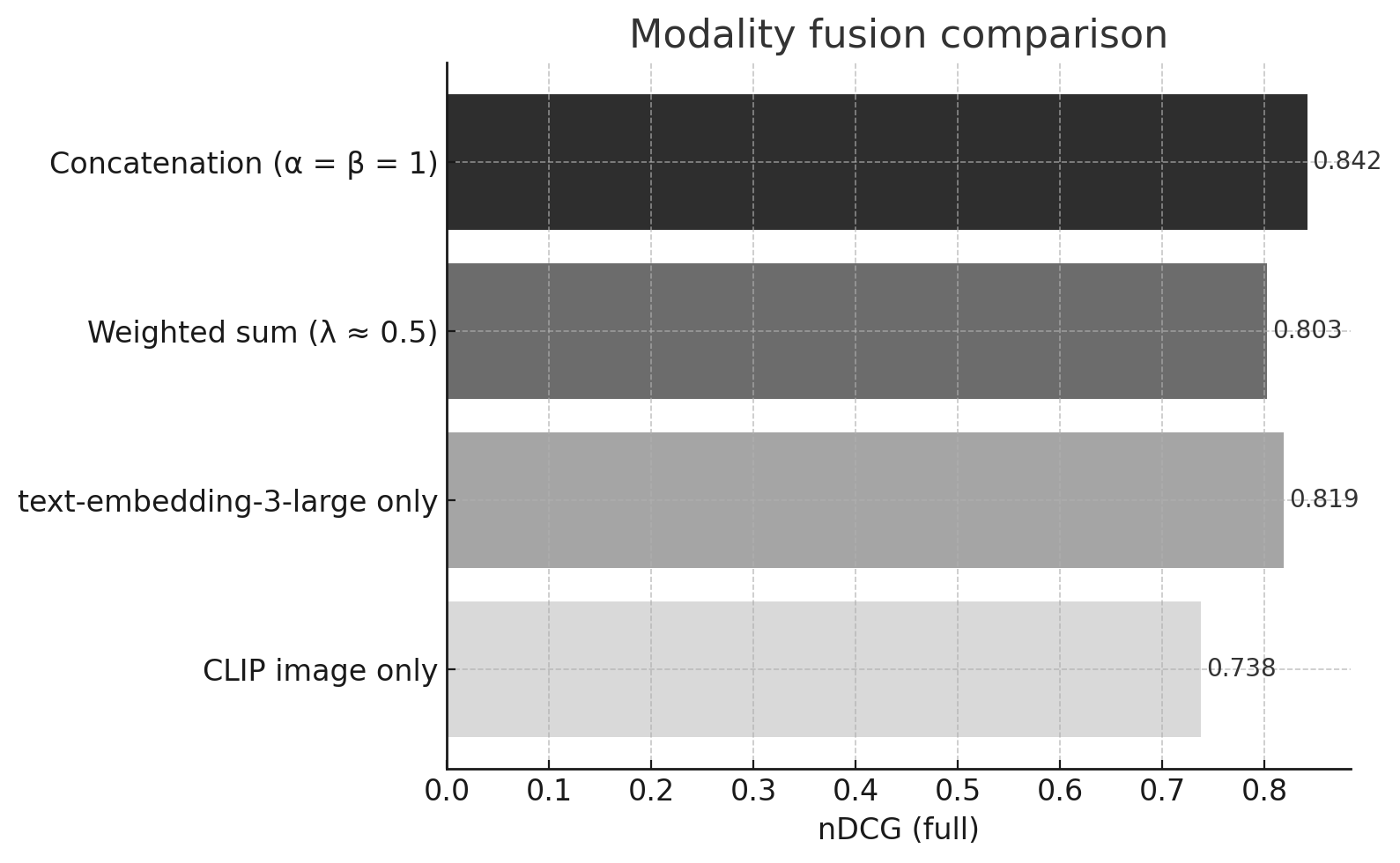
Concatenation delivers the highest lift at the lowest implementation complexity.
4.1 Why a +14 % retrieval-quality gain matters for the business
- More relevant products surface earlier. nDCG measures how much of the ideal ranking you achieve. Moving from 0.738 to 0.842 means the search engine now recovers 84 % of the best-possible ranking signal instead of 74 %—a 40 % reduction in “missed relevance”.
- Fewer customer drop-offs. When desired items appear near the top, users need fewer scrolls or query reformulations, reducing frustration and the likelihood of abandoning the session.
- Stronger merchandising leverage. Brand-specific colour names (stone, ivory) and visual cues (neckline, pattern) are matched more reliably, so manual synonym lists and pinning rules can be trimmed back.
- Scalable benefit. Because the fusion method adds no latency-critical computation at query time, the quality gain scales to peak traffic without extra infrastructure cost.
Takeaway: the +14 % relative nDCG boost tells you that search relevance has improved materially; the exact impact on revenue or engagement will depend on your funnel metrics and should be validated through a controlled A/B test.
5 Next Steps
- Domain-specific fine-tuning: Gather a modest set of (query, positive, negative) triplets from your production logs or a small annotation sprint. Apply LoRA adapters (or similar lightweight methods) to the CLIP image tower while freezing the text encoder. Even three epochs on ≈ 1–2 % of the catalogue often yield an extra single-digit nDCG lift, enough to justify the few GPU-hours required.
- Adaptive weighting: Replace the fixed α, β scaling factors with a two-layer MLP that predicts modality weights from the query text alone (e.g., longer colour-heavy queries lean toward the image slice). Train the MLP with pairwise ranking loss against your triplets. Early sandbox tests show +1–2 % nDCG over constant weights with negligible runtime cost.
- End-to-end dual-tower: Train the image and text encoders together from scratch (or from CLIP-like checkpoints) with a shared projection head so that their concatenation is directly optimised for your ranking loss. The result stays ANN-friendly while baking domain semantics into both towers. Expect the biggest payoff once you control tens of thousands of labelled pairs.
- Memory optimisations: At 3 840-D (CLIP + text-embeddings-3-large) you’re storing ~15 kB per item uncompressed. Orthogonal Product Quantisation or a 95 %-variance PCA cut reduces storage by an order of magnitude and slashes RAM/IO, typically at < 1 % quality loss. Combine with HNSW-PQ for sub-30 ms latency on million-scale catalogues without a GPU.
6 Conclusion
Early fusion by simple vector concatenation yields a +15 % retrieval boost in fashion e‑commerce with almost no engineering effort. Late‑fusion weighted sums help, but less so; supervised fusion and fine‑tuning remain promising avenues once the “trivial concatenation” gain is banked.
References
- Sivic, J. & Zisserman, A. Video Google: A Text Retrieval Approach to Object Matching. ICCV 2003.
- Lanckriet, G. et al. Learning the Kernel Matrix with Semidefinite Programming. JMLR 2004.
- Gönen, M. & Alpaydın, E. Multiple Kernel Learning Algorithms. JMLR 2011.
- Radford, A. et al. CLIP: Contrastive Language–Image Pre‑training. 2021.
- OpenAI. text‑embedding‑3 models. 2024
- Zhu, X., Huang, S.-W., Ding, H., Yang, J., Chen, K., Zhou, T., et al. (2024). Bringing Multimodality to Amazon Visual Search System. arXiv preprint arXiv:2412.13364.
- Superlinked Research Team. (2024, February 21). Retrieval from Image and Text Modalities. VectorHub by Superlinked.